配置Csv解析器解析各种Csv文件
22376人浏览 / 0人评论
请注意!FFReader不是一个通用的csv文件阅读软件,而是一个配置响应式的解析工具,也就是说,你想解析一个csv文件,首先要配置此类文件的解析规则
更新说明:FFReader正在向更多的领域发展,支持更多的数据解析,所以从1.9.1版本开始,也逐步支持了自动解析csv文件,对于竖线,逗号,制表符分割的文件,目前已经支持了较好的解析,欢迎下载使用
举例如下

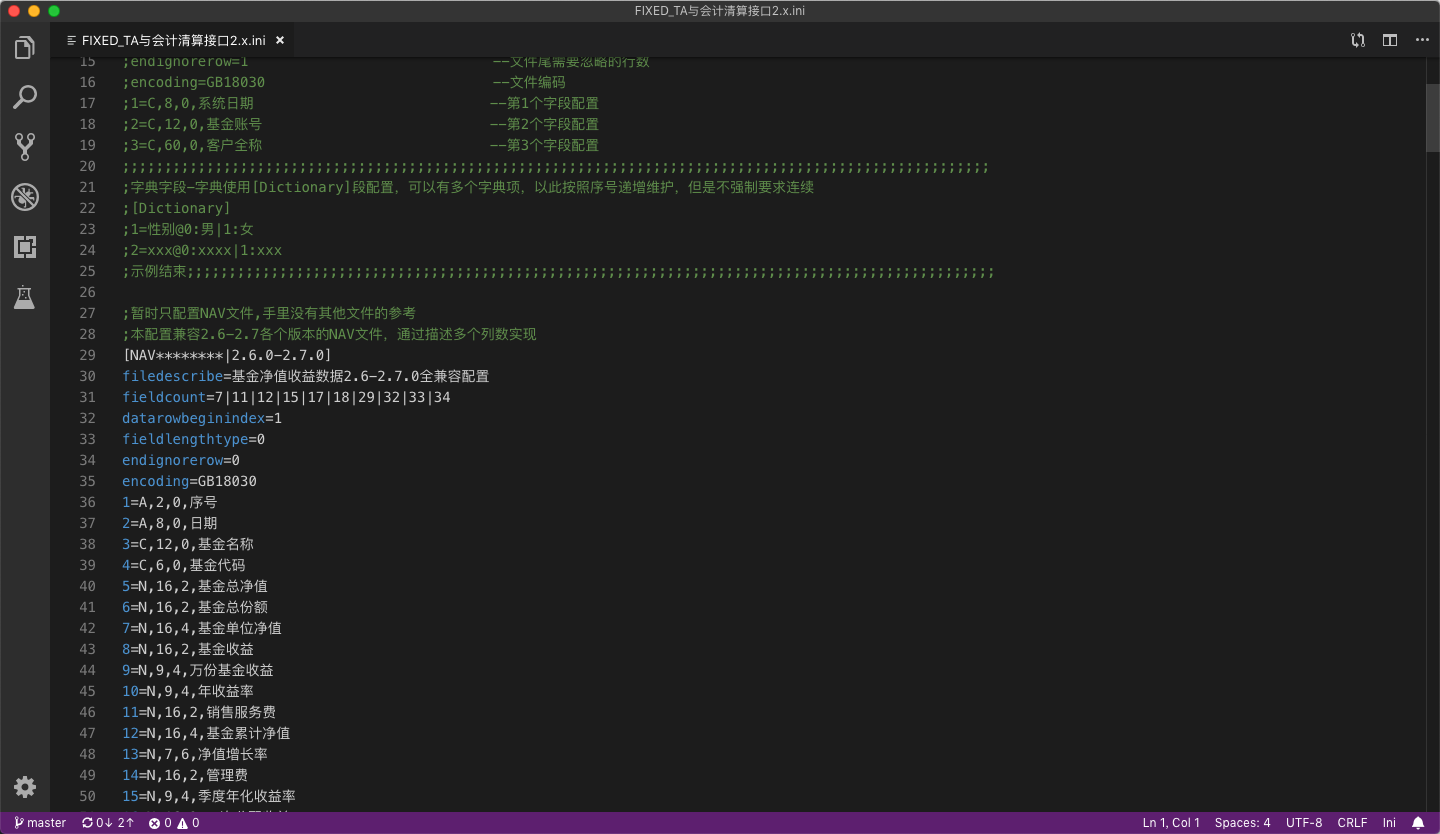
比如此文件是一个标准的数线分割文件,通过如下配置,就可以在FFReader中解析阅读此文件

如上是配置,如下是解析效果
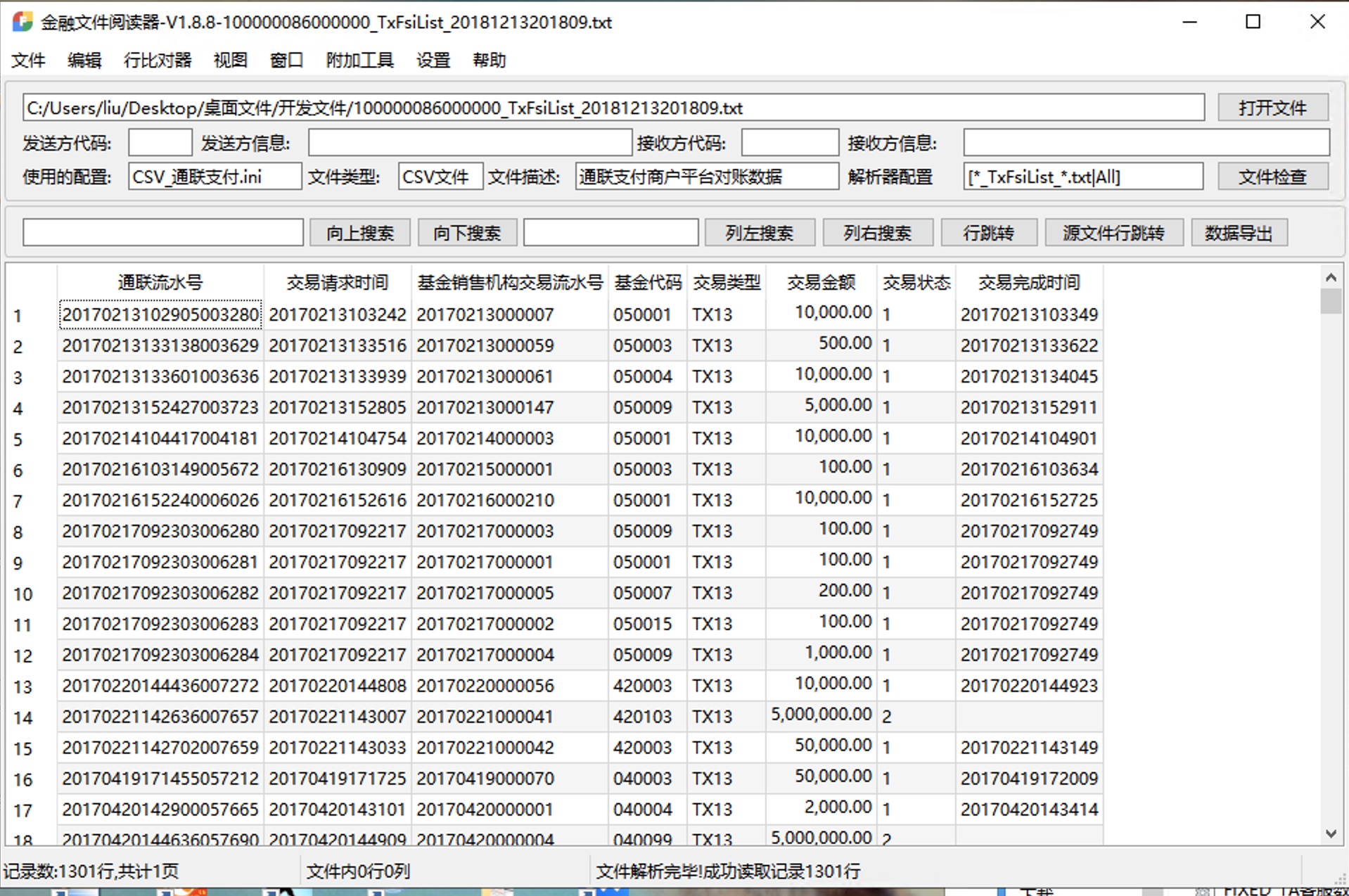
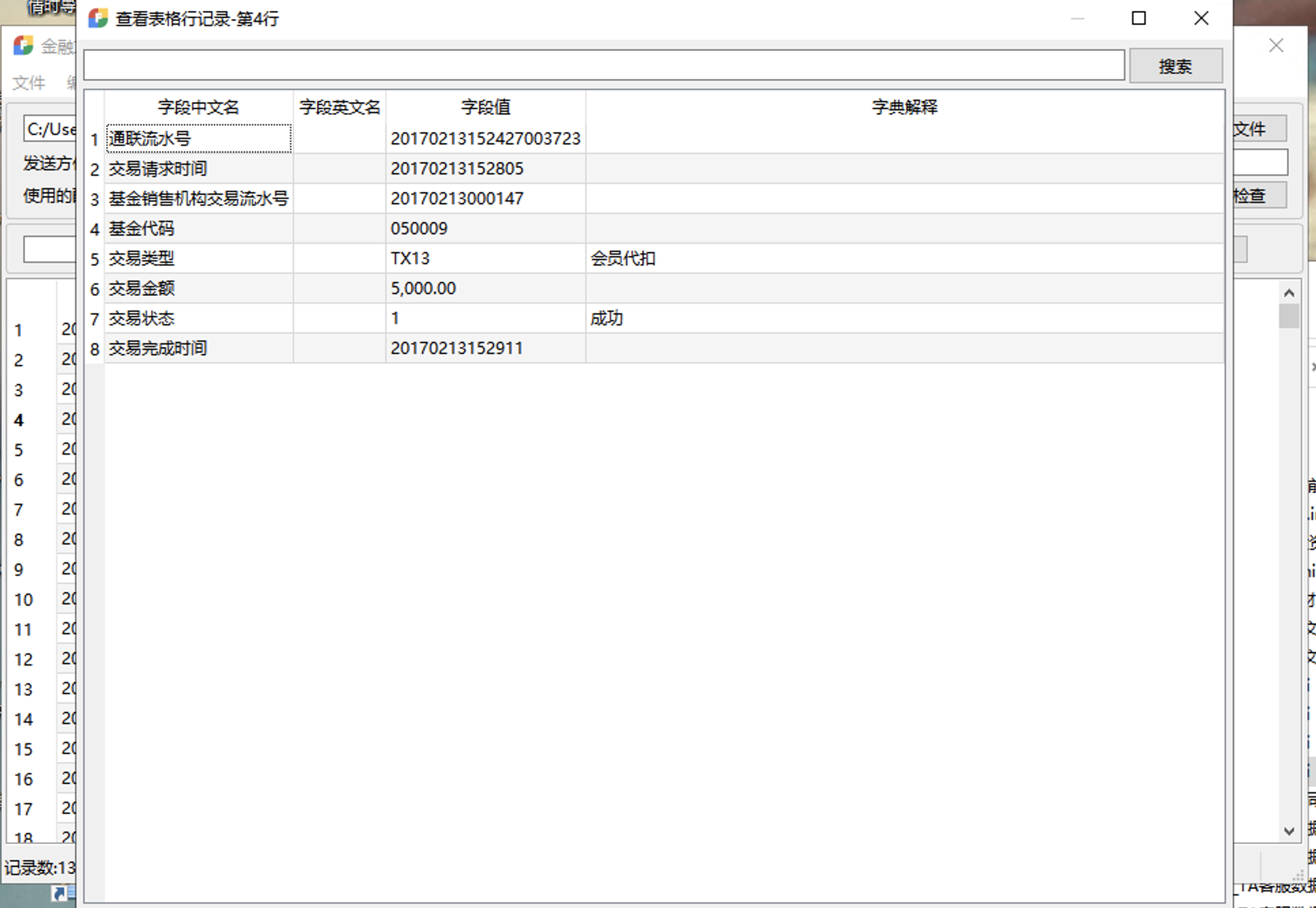
也就是说,FFReader在配置妥当的情况下,帮助你更好的阅览数据,自动字典翻译,还支持导出文件到excel,html
下面说说怎么配置~~~~
如果是一个老的接口类别,你可直接编辑已存在的配置文件,如果是新的接口类别,你可以在config下新增形如CSV_XXX系统.ini的配置,然后将新增的配置增加到里面
同一个配置文件即可配置某个系统所有的文件,以及所有的版本
针对某一个接口,一个完整的配置包含如下字段
[test_test_*_*.txt|V1.0] --此配置可以用于解析类文件名形如test_test_*_*.txt的csv文件*代表任意长度的任意字符(不包括空格等空白字符)V1.0是版本,也可以在这里写字段数,针对不同的字段数的文件做不同的配置,文件匹配名和版本之间竖线分开
filedescribe=交易记录文件 --此类文件的文件说明
fieldcount=10 这个文件里的数据每行有10列数据,如果文件内有标题行,直接设置列数为AUTO,则程序即可自动从文件内获取列数
titlerowindex=0 --如果文件内包含列标题行,则标题所在行号,0代表文件内无标题记录
datarowbeginindex=2 --此类文件第几行开始是数据记录行,不能小于1,否则强制判断为1
splitflag=| --此类文件内记录各个列之间的分隔符,常用(,逗号)(|竖线)( 制表符),不配置或者配置为空,则默认为,(逗号)分割
endwithflag=0 --此类文件每行最后是不是分隔符,如果是则为1
endignorerow=1 --文件尾部需要忽略的行,针对有文件尾的文件,可以配置忽略
encoding=UTF-8 --此类文件编码方式,诸如UTF-8,GB2312,GBK,GB18030等,不配置默认以UTF-8解析
1=交易账号 --第一列的列标题,注意,如果文件内存在标题行,则如下列标题可以不设置
2=原银行账号 --第二列的列标题
3=新银行账号 --第三列的列标题
4=原银行账号户名 --第四列的列标题
5=新银行账号户名 --第五列的列标题
6=原银行名称 --第六列的列标题
7=新银行名称 --第七列的列标题
8=原联行行号 --第八列的列标题
9=新联行行号 --第九列的列标题
10=原银行标志 --第十列的列标题
;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;;
注意:
如果文件内包含标题行,你可以将列数配置为AUTO,并且不再配置每列的字段描述,让程序自动去文件标题行获取
如果文件不包含标题行,建议在文件内明确配置每行的列数,当然也可以配置为AUTO,但是这个时候依然无法在配置文件里配置列描述信息